1. Introduction
The research on human detection, tracking, and reconstruction at the Intelligent Systems Laboratory includes human body detection and tracking, monocular 3D human body and hand reconstruction. We are honored to get our works supported by different governmental agencies including DARPA, ARO, ONR, AFOSR, DOT, and NSF.
2. Our Work
|
|
Knowledge-guide Learning of 3D Hand with Heteroscedastic 2D Hand Landmark Annotation |
This work is under review.
 |
Acquiring 3D data for fully-supervised monocular 3D hand reconstruction is often difficult, requiring specialized equipment for use in a controlled environment. In this work, we propose a novel methods for learning 3D hand solely utilizing 2D hand landmark annotation by effectively leveraging hand knowledge. Meanwhile, the uncertainty inherent in the 2D hand landmark is explictly modeling for improved training. Specifically,
- We identify valuable generic knowledge from a comprehensive study of hand literature, including hand biomechanics, functional anatomy, and physics.
- We introduce a set of differentiable training losses to effectively encode the identified knowledge into 3D reconstruction models.
- We exploit a simple yet effective NLL loss to improve the training by explicitly capturing the heteroscedastic uncertainty inherent in the supervision.
- We demonstrate through extensive experiments that the proposed method outperforms existing SOTAs by a large margin under the challenging weakly-supervised setting.
|
|
|
PhysPT: Physics-aware Pretrained Transformer for Estimating Human Dynamics from Monocular Videos |
This work is under review.
 |
While current methods have shown promising progress on estimating 3D human motion from monocular videos, their motion estimates are often physically unrealistic because they mainly consider kinematics. In this paper, we introduce Physics-aware Pretrained Transformer (PhysPT), which improves kinematics-based motion estimates and infers motion forces. PhysPT exploits a Transformer encoder-decoder backbone to learn human dynamics in a self-supervised manner and it incorporates physics principles governing human motion. Specifically,
- We introduce PhysPT, a Transformer encoder-decoder model trained through self-supervised learning with incorporation of physics. Once trained, PhysPT can be combined with any kinematic-based model to estimate human dynamics without additional model fine-tuning.
- We present a novel framework for incorporating physics. This includes a physics-based body representation and a contact force model, and, subsequently, the imposition of a set of novel physics-inspired losses for model training.
- We demonstrate through experiments that PhysPT significantly enhances the physical plausibility of kinematics-based estimates and infers motion forces. Furthermore, we demonstrate that the enhanced motion and force estimates translate into accuracy improvements in an important downstream task: human action recognition.
|
|
|
Body Knowledge and Uncertainty Modeling for 3D Body Reconstruction |
Yufei Zhang, Jeffrey O. Kephart, Hanjing Wang, Qiang Ji, ICCV 2023.
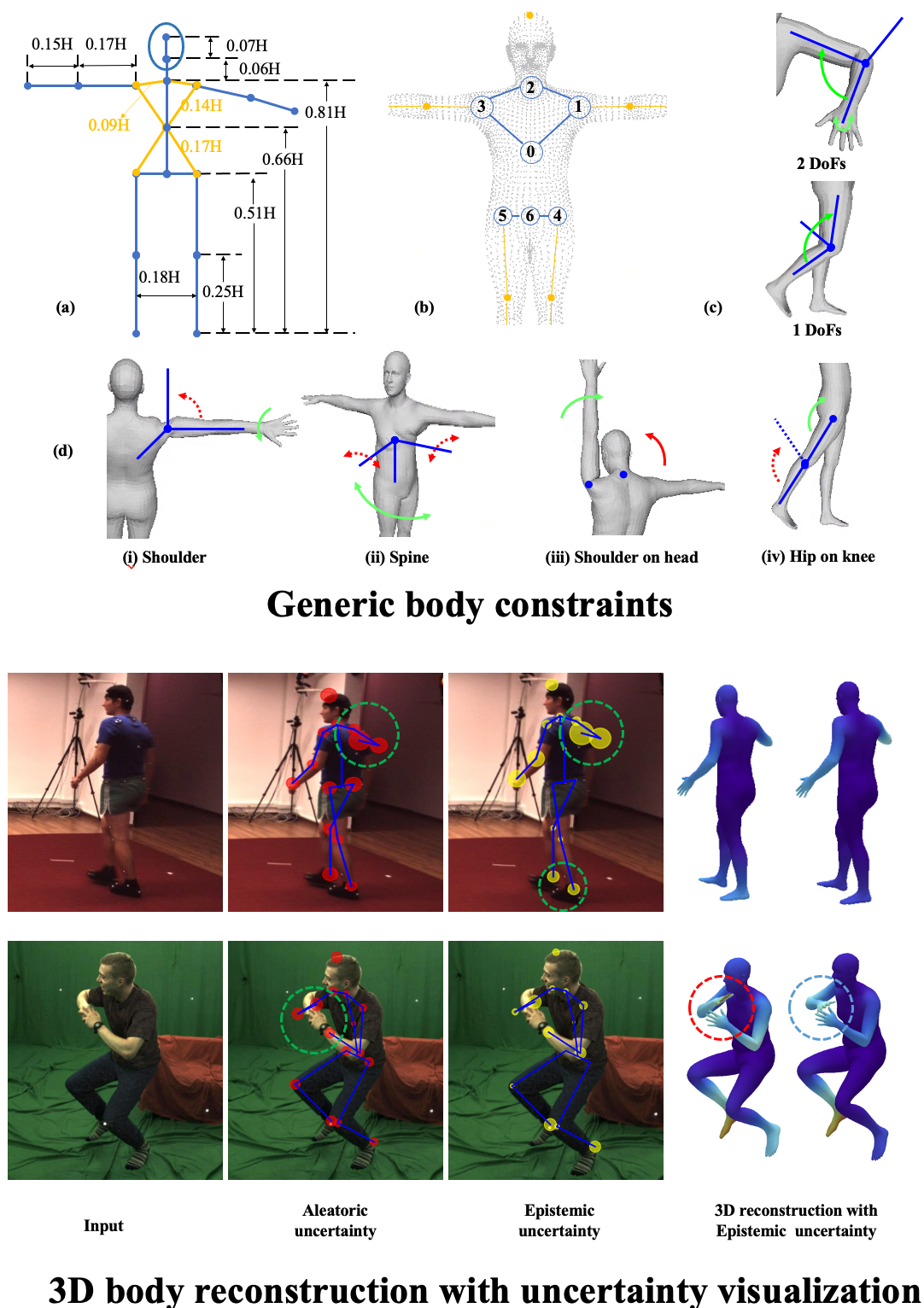 |
In this work, we focus on 3D human body reconstruction from a single RGB image. While 3D body reconstruction methods have made remarkable progress recently, it remains difficult to acquire the sufficiently accurate and numerous 3D supervisions required for training. To this end, We propose KNOWN, a framework that utilizes body KNOWledge and uNcertainty modeling to compensate for the lack of 3D supervision. Specifically,
- KNOWN introduces a comprehensive set of generic body constraints derived from well-established body knowledge. These generic, data-independent constraints enable training 3D reconstruction models with only 2D weak body landmark supervisions;
- KNOWN proposes a novel two-stage probabilistic framework that models epistemic and aleatoric uncertainty to handle labeling noise and dataset imbalance. Instead of using a traditional mean squared 2D projection error loss, KNOWN is trained with a robust Negative Log-Likelihood (NLL) loss and is further refined under the guidance of the estimated epistemic uncertainty;
- Through both aleatoric and epistemic uncertainty modeling, KNOWN can characterize images effectively. Experiments demonstrate that KNOWN's body reconstruction outperforms prior approaches, with significant advantages on minority images.
|
2.2 Human Body Detection and Tracking
|
|
Data-free Prior Model for Upper Body Pose Estimation and Tracking |
Jixu Chen; Siqi Nie; Qiang Ji, Data-Free Prior Model for Upper Body Pose Estimation and Tracking, IEEE Transaction on Image Processing, 2013.
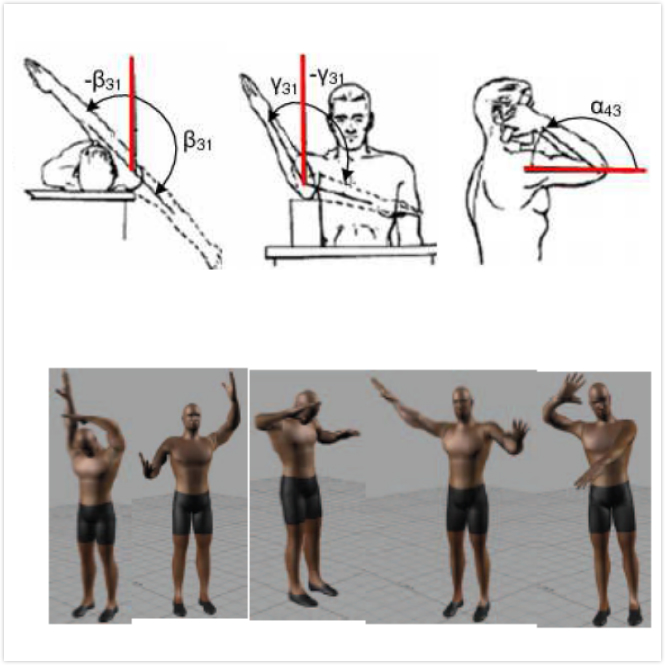 |
Video based human body pose estimation seeks to estimate the human body pose from an image or a video sequence, which captures a person exhibiting some activities. In order to handle noise and occlusion, a pose prior model is often constructed and the prior model is subsequently combined with the pose estimated from the image data to achieve a more robust body pose tracking. Various body prior models have been proposed. Most of them are data-driven, typically learned from the 3D motion capture data. In addition to being expensive and time-consuming to collect, these data-based prior models cannot generalize well to activities and subjects not present in the motion capture data. To alleviate this problem, we propose to learn the prior model from basic principles that govern the body pose and its movement, rather than from the motion capture data.
- These principles are derived from anatomy, biomechanics and physics theories. For this, we propose a framework and methods that can simultaneously capture different types of domain knowledge and systematically embed them into the prior model.
- Experiments on benchmark datasets show the proposed prior model, compared with current data-based prior models, achieves comparable performance for body motions that are present in the training data. It, however, significantly outperforms the data-based prior models in generalization to different body motions and to different subjects.
- The proposed framework can be applied to other vision problems, where the required training data is limited or difficult to acquire but much domain knowledge is readily available.
|
|
|
3D Upper Body Tracking with Self-Occlusions |
Jixu Chen and Qiang Ji, Efficient 3D Upper Body Tracking with Self-Occlusions, International Conference on Pattern Recognition, 2010.
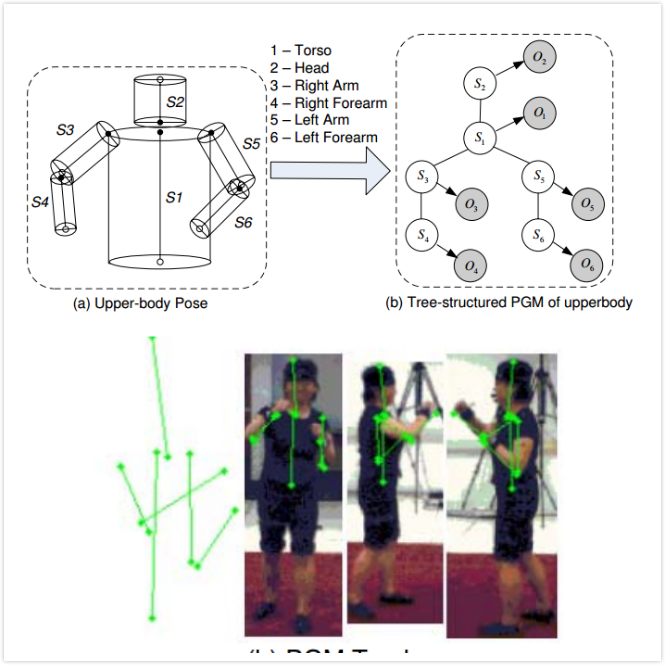 |
We proposed an efficient 3D upper body tracking method, which recovers the positions and orientations of six upper-body parts from the video sequence. Our method is based on a probabilistic graphical model(PGM), which incorporates the spatial relationships among the body parts, and a robust multi-view image likelihood using probabilistic PCA (PPCA). For the efficiency, we use a tree-structured graphical model and use the particle based belief propagation to perform the inference. Since our image likelihood is based on multiple views, we address the self-occlusion by modeling the likelihood of the body part in each view, and automatically decrease the influence of the occluded view in the inference procedure.
|
|
|
Switching Gaussian Process for Motion Tracking |
Jixu Chen, Minyoung Kim, Yu Wang, and Qiang Ji, Switching Gaussian Process Dynamic Models for Simultaneous Composite Motion Tracking and Recognition, IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2009.
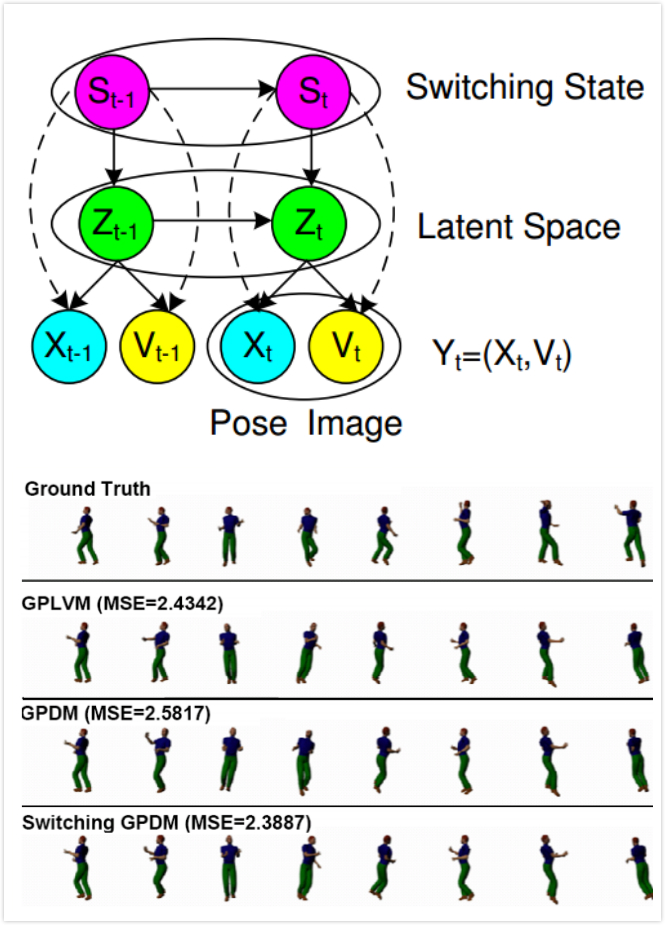 |
In this work, we proposed the marriage of the switching dynamical system and recent Gaussian Process Dynamic Models (GPDM), yielding a new model called the switching GPDM (SGPDM).
- The proposed switching variables enable the SGPDM to capture diverse motion dynamics effectively, and also allow to identify the motion class(e.g. walk or run in the human motion tracking, smile or angry in the facial motion tracking), which naturally leads to the idea of simultaneous motion tracking and classification.
- Each of GPDMs in SGPDM can faithfully model its corresponding primitive motion, while performing tracking in the low-dimensional latent space, therefore significantly improving the tracking efficiency.
- The proposed SGPDM is then applied to human body motion tracking and classification, and facial motion tracking and recognition. We demonstrate the performance of our model on several composite body motion videos obtained from the CMU database, including exercises and salsa dance.
- We also demonstrate the robustness of our model in terms of both facial feature tracking and facial expression/pose recognition performance on real videos under diverse scenarios including pose change, low frame rate and low quality videos.
|
|
|
Dynamic Bayesian Network (DBN) for Upper Body Tracking |
Lei Zhang, Jixu Chen, Zhi Zeng, and Qiang Ji, 2D and 3D Upper Body Tracking with One Framework, International Conference on Pattern Recognition, 2008.
 |
We proposed a Dynamic Bayesian Network (DBN) model for upper body tracking.
- We first construct a Bayesian Network (BN) to represent the human upper body structure and then incorporate into the BN various generic physical and anatomical constraints on the parts of the upper body. Unlike the existing upper body models, ours aims at handling physically feasible body motion rather than only some typical motion patterns.
- We also explicitly model part self-occlusion in the DBN model, which allows to automatically detect the occurrence of self-occlusion and to minimize the effect of measurement errors on the tracking accuracy due to occlusion.
- Our method can handle both 2D and 3D upper body tracking within the same framework. Using the DBN model, upper body tracking can be achieved through probabilistic inference over time.
|
|
|
Spatial-temporal Context based Multi-people Detection and Tracking |
Hieu T. Nguyen Qiang Ji, and Arnold W.M. Smeulders, Spatio-Temporal Context for Robust Multitarget Tracking, IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, 2007.
 |
The problem of human detection in video from a distance has been extensively investigated within the computer vision community. It is difficult because of the large variations in human appearance due to changes in illumination, camera position, clothing and body pose, and the motion of the platform (such as ship). To overcome these difficulties, we develop a new approach by incorporating the context information. Specifically, the context of a target in an image sequence has two components: the spatial context including the local background and nearby targets and the temporal context including all appearances of the targets that have been seen previously. A new model for multi-target tracking based on the classification of each target against its spatial context was implemented. The temporal context is included by integrating the entire history of target appearance based on probabilistic principal component analysis (PPCA). A new incremental scheme has been developed that learns the full set of PPCA parameters accurately online. Experimental results on both visible and thermal videos demonstrate the superior performance of our approach to the existing techniques in tracking small targets from distance with complex background.
|
