Spontaneous
Facial Action Modeling and Understanding by A Dynamic
Bayesian Network
Facial action is one of the
most important sources of information for understanding emotional state and
intention [1]. Spontaneous facial action is characterized by rigid head
movement, nonrigid facial muscular movements, and their
interactions. Rigid head movement characterizes the overall 3D head pose
including rotation and translation. Nonrigid facial
muscular movement results from the contraction of facial muscles and
characterizes the local facial action at a finer level. The Facial Action
Coding System (FACS) developed by Ekman and Friesen
[2] is the most commonly used system for measuring facial behavior. Based on
FACS, nonrigid facial muscular movement can be
described by 44 facial action units (AUs), each of
which is anatomically related to the contraction of a specific set of facial
muscles.
Why we recognize spontaneous facial action?
An objective and noninvasive
system for facial action understanding has applications in human behavior
science, human-computer interaction, security, interactive games, computer-based
learning, entertainment, telecommunication, and psychiatry.
Challenges of recognizing spontaneous facial action
- Facial actions are rich and complex.
- Spontaneous facial expressions often cooccur with natural head movement when people communicate with others.
- Most of the spontaneous facial expressions are activated without significant facial appearance changes.
- Spontaneous facial expression may have multiple apexes, and multiple facial expressions often occur sequentially.
- The subtle facial
deformations and frequent head movements make it more difficult to label
the facial expression data.
Facial action modeling
Due to the low intensity, nonadditive effect, and individual difference of the
spontaneous facial action as well as the image uncertainty, individually
recognizing facial action is not accurate and reliable. Hence, understanding
spontaneous facial action requires not only improving facial motion
measurements, but more importantly, requires exploiting the spatial-temporal
interactions among facial motions since it is these coherent, coordinated, and
synchronized interactions of facial motions that produce a meaningful facial
display. By explicitly modeling and using these relationships, we can improve
facial action recognition performance by compensating erroneous or missing
facial motion measurements.
Figure 1 presents the complete DBN model for facial action modeling. Specifically, there are three layers in the proposed model:
- The first layer consists of the 3D head pose, 3D facial shape, and the 2D global shape Sg, and it models the effect of rigid head motion and the 3D facial shape on the 2D global shape.
- The second layer contains a set of 2D local shapes corresponding to the facial components as well as their relationships to the global shape.
- The third layer includes a set of AUs and their spatial interactions and dynamic interactions through the dynamic links. The third layer also models the effect of AUs on the shapes of local facial components through the intermediate nodes.
We employ the first layer as
the global constraint for the overall system so that it will guarantee globally
meaningful facial action. Meanwhile, the local structural details of the facial
components are constrained not only by the local shape parameters, but also are
characterized by the related AUs through the
interactions between the second layer and the third layer. In addition, the
interactions between the rigid head motion and the nonrigid
facial actions are indirectly modeled through the 2D global and local facial component
shapes. Finally, the facial motion measurements are systematically incorporated
into the model through the shaded nodes. This model, therefore, completely
characterizes the spatial and temporal dependencies between rigid and nonrigid facial motions and accounts for the uncertainties
in facial motion measurements.

Fig. 1. The complete DBN model for facial action understanding. The shaded node indicates the observation for the connected hidden node. The self-arrow at the hidden node represents its temporal evolution from previous time frame to the current time frame. The link from AUi at time t-1 to AUj (j ¹ i) at time t indicates the dynamic dependency between different AUs.
Facial action recognition by exploiting the
spatial-temporal interactions among facial motions
Figure 2 shows the proposed facial
action recognition system. In the system, various computer vision techniques are
used to obtain measurements of both rigid (head pose) and nonrigid
facial motions (AUs). These measurements are then
used as evidences by the facial action model for inferring the true states of
the rigid head pose and the nonrigid AUs simultaneously.
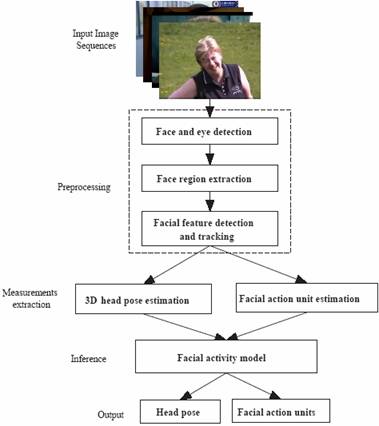
Fig. 2. The
flowchart of the facial action recognition system.
Experimental results
(1)
Evaluation on ISL multiview facial expression
database
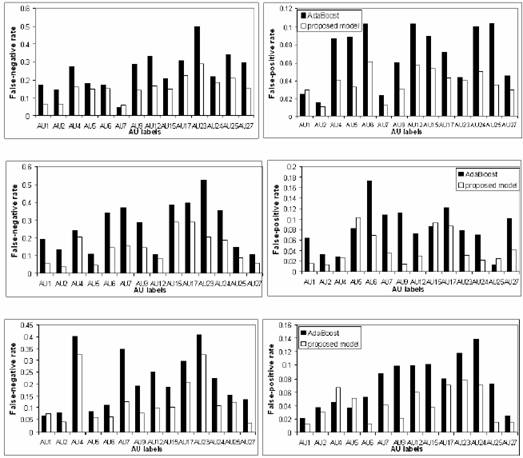
In order to demonstrate the robustness of the proposed system, we perform experiments on ISL multiview facial expression database under realistic environment where the face undergoes facial expression and face pose changes. The system performance is reported in Figure 3.
Compared to the AU recognition
by using the AdaBoost classifiers only, we can find
that: (1) for the frontal-view face, the average relative false-negative rate
(error rate of positive samples) decreases by 37.5%, and the average relative
false-positive rate (error rate of negative samples) decreases by 44.7%; (2)
for the right-view face, the average relative false-negative rate decreases by
40%, and the average relative false-positive rate decreases by 42.2%; and (3)
for the left-view face, the average relative false-negative rate decreases by
46.1%, and the average relative false-positive rate decreases by 46.8% by using
the proposed model. Here, the relative error rate is defined as the ratio of
the error rate of the proposed method to the error rate of the AdaBoost method. Especially for the AUs
that are difficult to be recognized, the system performance is greatly
improved. For example, for AU23 (lip tighten), its false-negative rate
decreases from 52.3% to 20.5%, and its false-positive rate decreases from 7.7% to
3.1% for the left view face; the false-negative rate of AU7 (lid tighten)
decreases from 34.8% to 12.5% for the right view face; and the false-negative
rate of AU6 (cheek raiser and lid compressor) is decreased from 34% to 14.5%
with a significant drop of false-positive rate decreasing from 17.3% to 6.95%
for the left view face.
(a) (b)
Fig. 3.
AU recognition results under realistic circumstance for frontal-view faces (top
row), left-view faces (middle row), and right-view faces (bottom row). In each figure,
the black bar denotes the result by the AdaBoost
classifier, and the white bar represents the result by using the proposed
model. (a) The first column demonstrates average false-negative rate. (b) The
second column displays average false-positive rate.
(2)
Evaluation on a spontaneous facial expression database
Instead of recognizing posed
facial activities, it is more important to recognize spontaneous facial actions.
Therefore, in the second set of the experiments, the system is trained and
tested on a spontaneous facial expression database to demonstrate the system
robustness for recognizing spontaneous facial action.
Publications:
- Y. Tong, W. Liao, Z. Xue, and Q. Ji, A Unified Probabilistic Framework
for Facial Activity Modeling and Understanding, Proc. IEEE Int'l Conf.
Computer Vision and Pattern Recognition (2007).
Useful Links for AUs
recognition:
- Machine Perception Laboratory
- CMU robotics institute
- Man-Machine Interaction Group
- http://www.irc.atr.jp/~mlyons/facial_expression.html
- http://mambo.ucsc.edu/psl/fanl.html
Facial expression image database
- Japanese
female facial expressions database
- AR database
- Cohn-Kanade AU-Coded
Facial Expression Database
- MMI Face Database
- ISL Facial Expression
Database
Reference:
[1] M. Pantic and M. Bartlett, “Machine
analysis of facial expressions,” in Face Recognition, K. Delac and M. Grgic, Eds.
[2]
P. Ekman and W. V. Friesen, Facial Action Coding
System: A Technique for the Measurement of Facial Movement. Palo
Alto,
CA: Consulting Psychologists Press, 1978.