
Facial landmark detection and tracking is an active area in computer vision, due to its relevance to many applications such as head pose estimation and facial expression recognition. The goal is to detect and track a few landmarks on the facial images as shown in Figure 1. Facial landmark detection and tracking are challenging problems, since the faces can change significantly under varying facial expressions, head poses, facial occlusions and illumination conditions. To tackle those problems, we propose several sets of methods. Depending on the purposes of the algorithms, they can be further classified into methods that handle varying expressions and poses, methods for handling facial occlusion, and others.
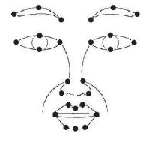
Figure 1. Facial landmarks that we aim to detect and track.
Facial landmark detection is a difficult task, since the facial appearance and shapes vary significantly with facial expressions and head poses. To tackle this problem, we propose several methods.
In the first set of works [1-4], we propose an effective approach to detect and track twenty-eight facial features from the face images with different facial expressions under various face orientations in real time. The improvements in facial feature detection and tracking accuracy are resulted from: (1) combination of the Kalman filtering with the eye positions to constrain the facial feature locations; (2) the use of pyramidal Gabor wavelets for efficient facial feature representation; (3) dynamic and accurate model updating for each facial feature to eliminate any error accumulation; (4)imposing the global geometry constraints to eliminate any geometrical violations (Figure 2). By these combinations, the accuracy of the facial feature tracking reaches a practical acceptable level. Subsequently, the extracted spatio-temporal relationships among the facial features can be used to conduct the facial expression classification successfully.
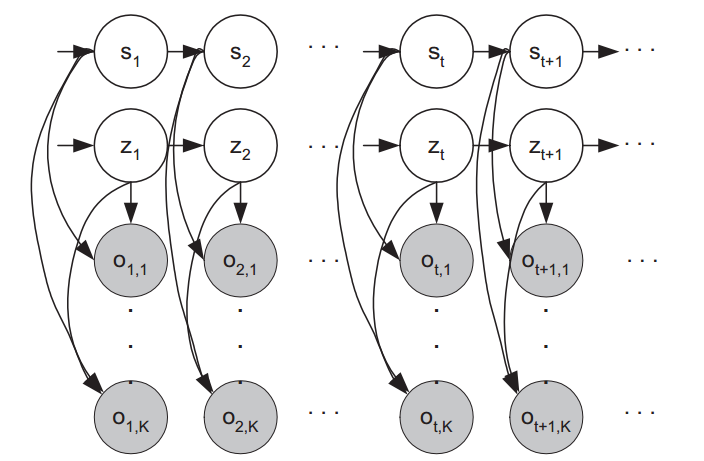
Figure 2. The dynamic probabilistic facial shape model that can switch between different states.
In the second work [5], we propose a hierarchical probabilistic model to capture the large shape variations due to expressions and head poses. Through the model, we could infer the true locations of facial features given the image measurements even if the face is with significant facial expression and pose (Figure 2). The hierarchical model implicitly captures the lower level shape variations of facial components using the mixture model. Furthermore, in the higher level, it also learns the joint relationship among facial components, the facial expression, and the pose information through automatic structure learning and parameter estimation of the probabilistic model (nodes in the dotted rectangular in Figure 2). Experimental results on benchmark databases demonstrate the effectiveness of the proposed hierarchical probabilistic model.
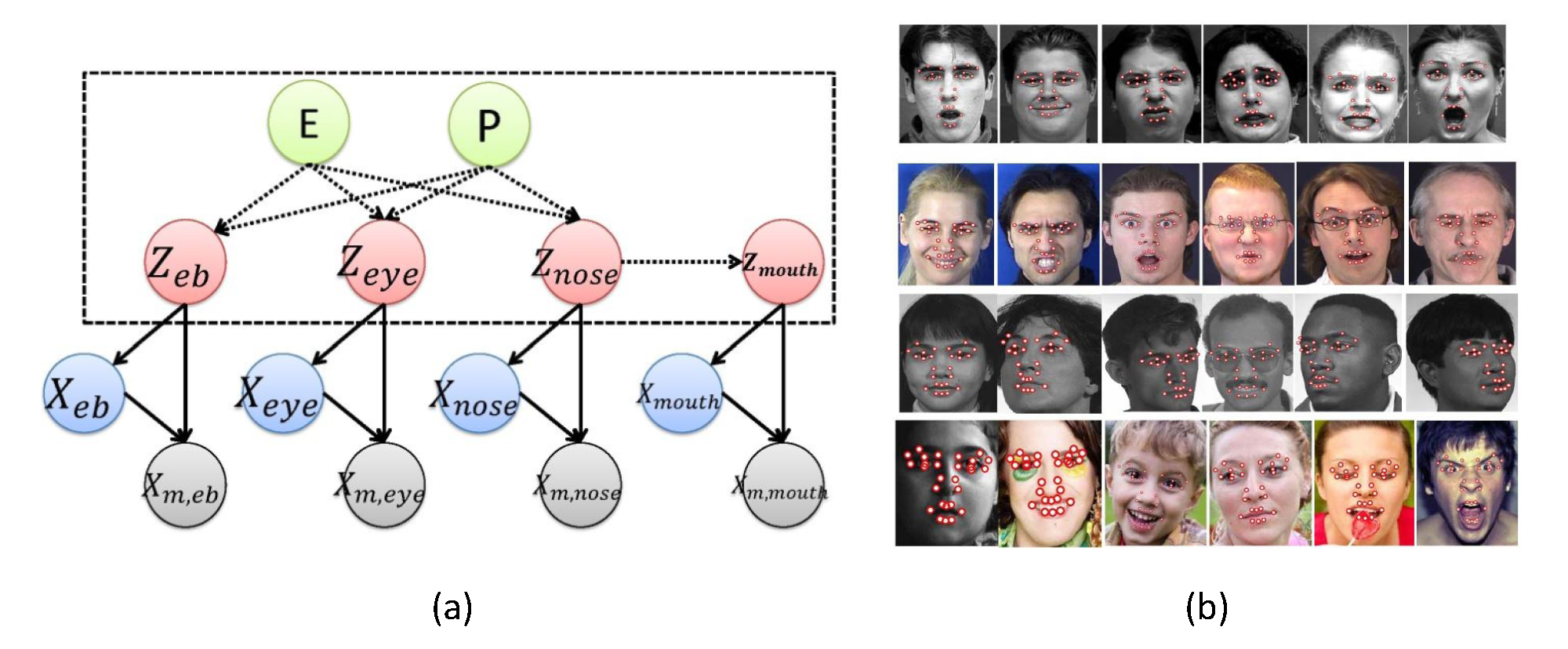
Figure 3. (a) The hierarchical probabilistic model for facial landmark detection under varying facial expressions and head poses. Nodes on the first (bottom) layer represent the measurements of facial landmark locations from the local point detectors. Nodes on the second layer represent the ground truth facial landmark locations we want to infer. Nodes on the third layer are discrete hidden nodes representing the states of different facial components (e.g., mouth open and closed). Nodes on the top layer represent the facial expression and head pose labels. Nodes on the lower three layers captures the local shape variations, while nodes on the top two layers capture the global relationships. (b) Experimental results on benchmark databases (e.g., CK+, MMI, FERET and AFLW).
In the third work [6-7], to capture the large facial shape variations due to expressions and head poses, we proposed a discriminative deep face shape model that is constructed based on an augmented factorized three-way Restricted Boltzmann Machines model (Figure 3). Specifically, the discriminative deep model combines the top-down information from the embedded face shape patterns and the bottom up measurements from local point detectors in a unified framework. In addition, it implicitly decouples the face shapes into expression-related parts and pose-related parts with the help of additional frontal face shapes. Along with the model, effective algorithms are proposed to perform model learning and to infer the true facial point locations from their measurements. Based on the discriminative deep face shape model, 68 facial points are detected on facial images in both controlled and ''in-the-wild'' conditions. Experiments on benchmark data sets show the effectiveness of the proposed facial point detection algorithm against state-of-the-art methods.

Figure 4. (a) The proposed discriminative deep face shape model. It consists of a factorized three-way RBM connecting the arbitrary facial shape (x), the corresponding frontal facial shape (y), and the hidden nodes (h1). It also includes two RBMs that model the connections among the arbitrary facial shape (x), the hidden nodes (h2), and the measurements of the arbitrary facial shape (m). (b) Arbitrary facial shape and its corresponding frontal facial shape for the same subject and expression. (c) Experimental results on benchmark databases (e.g., MultiPIE, Helen, LFPW and AFW).
There have been tremendous improvements for facial landmark detection on general ''in-the-wild'' images. However, it is still challenging to detect the facial landmarks on images with severe occlusion and images with large head poses (e.g. profile face). In fact, the existing algorithms usually can only handle one of them. In this work [8-9], we propose a unified robust cascade regression framework that can handle both images with severe occlusion and images with large head poses (Figure 4). Specifically, the method iteratively predicts the landmark occlusions and the landmark locations. For occlusion estimation, instead of directly predicting the binary occlusion vectors, we introduce a supervised regression method that gradually updates the landmark visibility probabilities in each iteration to achieve robustness. In addition, we explicitly add occlusion pattern as a constraint to improve the performance of occlusion prediction. For landmark detection, we combine the landmark visibility probabilities, the local appearances, and the local shapes to iteratively update their positions. The experimental results show that the proposed method is significantly better than state-of-the-art works on images with severe occlusion and images with large head poses. It is also comparable to other methods on general ''in-the-wild'' images.

Figure 5. Facial landmark detection under facial occlusion. (a) The proposed method iteratively predicts the facial landmark locations and facial landmark visibility probabilities. (b) Experimental results on benchmark databases (e.g., COFW, FERET, Helen and LFPW).
Facial action unit recognition and facial landmark detection are two related tasks for face analysis. But, they are seldomly exploited together. In this work [10], we improve upon the cascade regression framework and propose the Constrained Joint Cascade Regression Framework (CJCRF) for simultaneous facial action unit recognition and facial landmark detection (Figure 5). In particular, we first learn the relationships among facial action units and face shapes as a constraint. Then, in the proposed constrained joint cascade regression framework, with the help from the constraint, we iteratively update the facial landmark locations and the action unit activation probabilities until convergence. Experimental results demonstrate that the intertwined relationships of facial action units and face shapes boost the performances of both facial action unit recognition and facial landmark detection. The experimental results also demonstrate the effectiveness of the proposed method comparing to the state-of-the-art works.
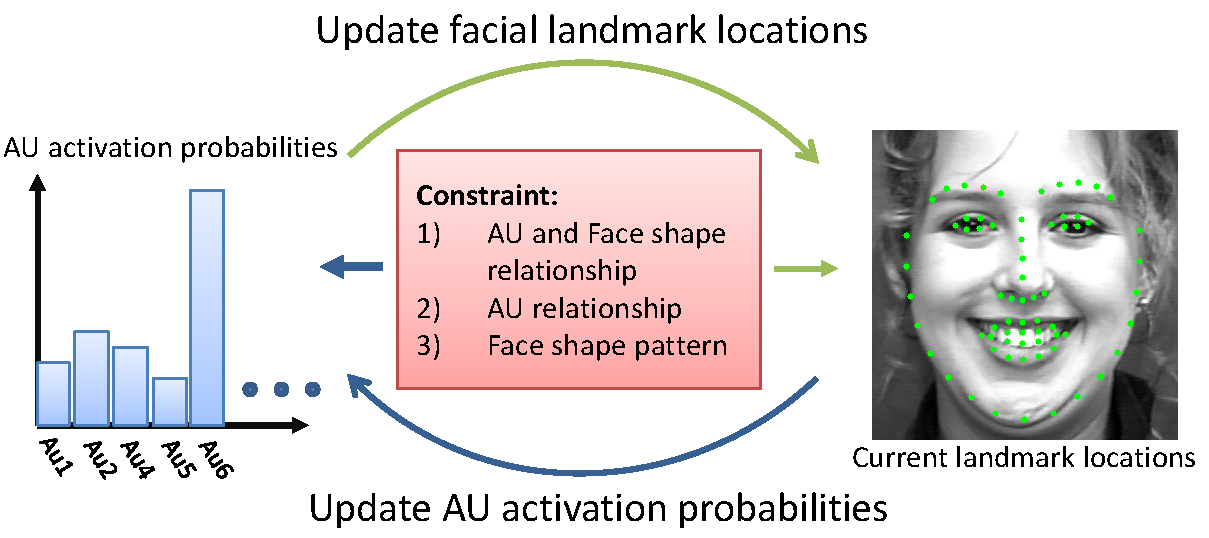
Figure 6. Joint facial landmark detection and action unit recognition.
[1] Yan Tong, Yang Wang, Zhiwei Zhu, and Qiang Ji, ''Robust Facial Feature Tracking under Varying Face Pose and Facial Expression,'' Pattern Recognition, Vol. 40, No. 11, pp. 3195-3208, November 2007. PDF
[2] Zhiwei Zhu and Qiang Ji, ''Robust Pose Invariant Facial Feature Detection and Tracking in Real-Time,'' the 18th International Conference on Pattern Recognition (ICPR), Hongkong, August, 2006. PDF
[3] Yan Tong, Yang Wang, Zhiwei Zhu, and Qiang Ji, ''Facial Feature Tracking using a Multi-State Hierarchical Shape Model under Varying Face Pose and Facial Expression,'' the 18th International Conference on Pattern Recognition (ICPR), Hongkong, August, 2006. PDF
[4] Yan Tong and Qiang Ji, ''Multiview Facial Feature Tracking with a Multi-modal Probabilistic Model,'' the 18th International Conference on Pattern Recognition (ICPR), Hongkong, August, 2006. PDF
[5] Yue Wu, Ziheng Wang, and Qiang Ji, ''A Hierarchical Probabilistic Model for Facial Feature Detection,'' IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014. PDF
[6] Yue Wu, Zuoguan Wang, and Qiang Ji, ''Facial Feature Tracking under Varying Facial Expressions and Face Poses based on Restricted Boltzmann Machines,'' IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013. PDF
[7] Yue Wu and Qiang Ji, ''Discriminative Deep Face Shape Model for Facial Point Detection,'' International Journal of Computer Vision (IJCV), Vol. 113, Issue 1, pp 37-53, May 2015. PDF
[8] Yue Wu and Qiang Ji, ''Robust Facial Landmark Detection under Significant Head Poses and Occlusion,'' International Conference on Computer Vision (ICCV), 2015. PDF
[9] Yue Wu and Qiang Ji, ''Shape Augmented Regression Method for Face Alignment,'' 300 Videos in the Wild (300-VW) Challenge and Workshop, International Conference on Computer Vision Workshop(ICCVW), 2015.
[10] Yue Wu and Qiang Ji, ''Constrained Joint Cascade Regression Framework for Simultaneous Facial Action Unit Recognition and Facial Landmark Detection,'' IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. PDF